



背景
最近我们开发了一个摄影类的H5应用,其中涉及大量图片的上传和下载操作。该应用的服务端由我负责,而图片文件存储在企业私有云的对象存储服务(OSS)中。这个OSS是无法通过互联网访问的,只能在内网使用。因此,不论是上传还是下载图片,都必须通过应用的服务端进行中转,同时进行一些图片校验等操作。
项目紧急需要上线,我在完成第一版代码通过了测试后立即进行了发布和部署。
一、项目的一些基本设置
1.1 JDK版本
项目基于JDK1.8进行开发,服务器的JRE版本也是1.8。
1.2 服务器基本信息
服务器运行在CentOS 7系统上,采用4核8G的ECS,部署在某企业私有云内,使用传统的集群部署方式,并通过SLB实现负载均衡以及内网穿透。
1.3 JVM参数
在第一版中,我使用了以下JVM参数设置。鉴于项目急需上线,且用户规模不大,我选择了之前通用的参数配置。
二、发现了问题
上周五匆匆发了一个版本后就回家了。今天登录系统时,发现系统居然卡住了,刷新了一会才恢复正常。我猜测可能是由于GC导致的,于是我查看了线上GC统计数据,结果让我大吃一惊!
首先,我先分享一下在 gceasy.io 上的分析结果,这是其中一台发生 Full GC 次数最多的服务器的情况。

由于这个日志的时间跨度为83小时,是在周四晚上部署后至周一检查的。
看一下这糟糕的停顿时间和停顿次数…
2.1 年轻代GC前后的内存对比
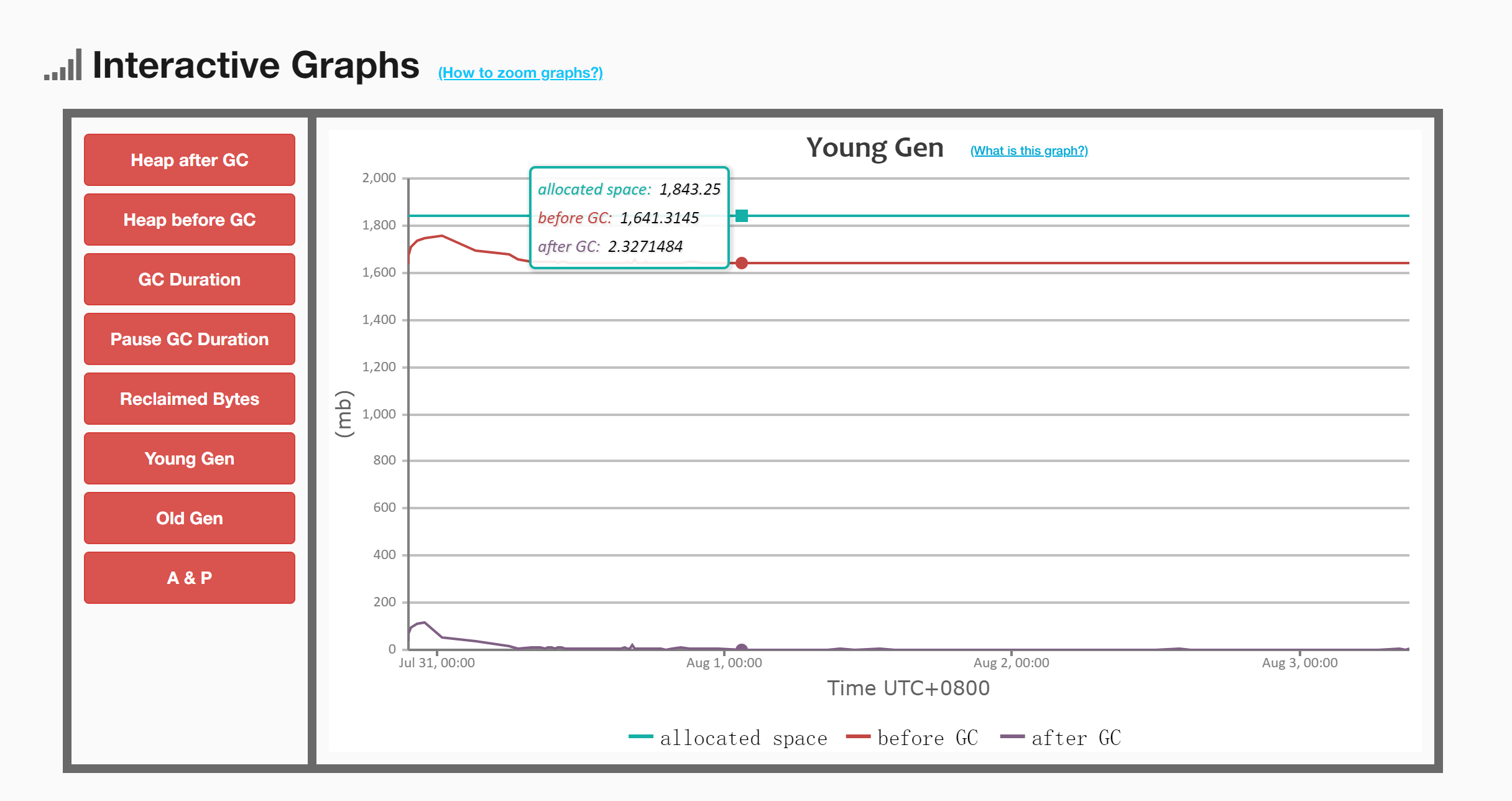
可以观察到,在Young GC之后,内存变化相当大,这表明年轻代的对象绝大部分都被清理掉了,说明GC是起到了一定效果的。
2.2 老年代GC前后的内存对比
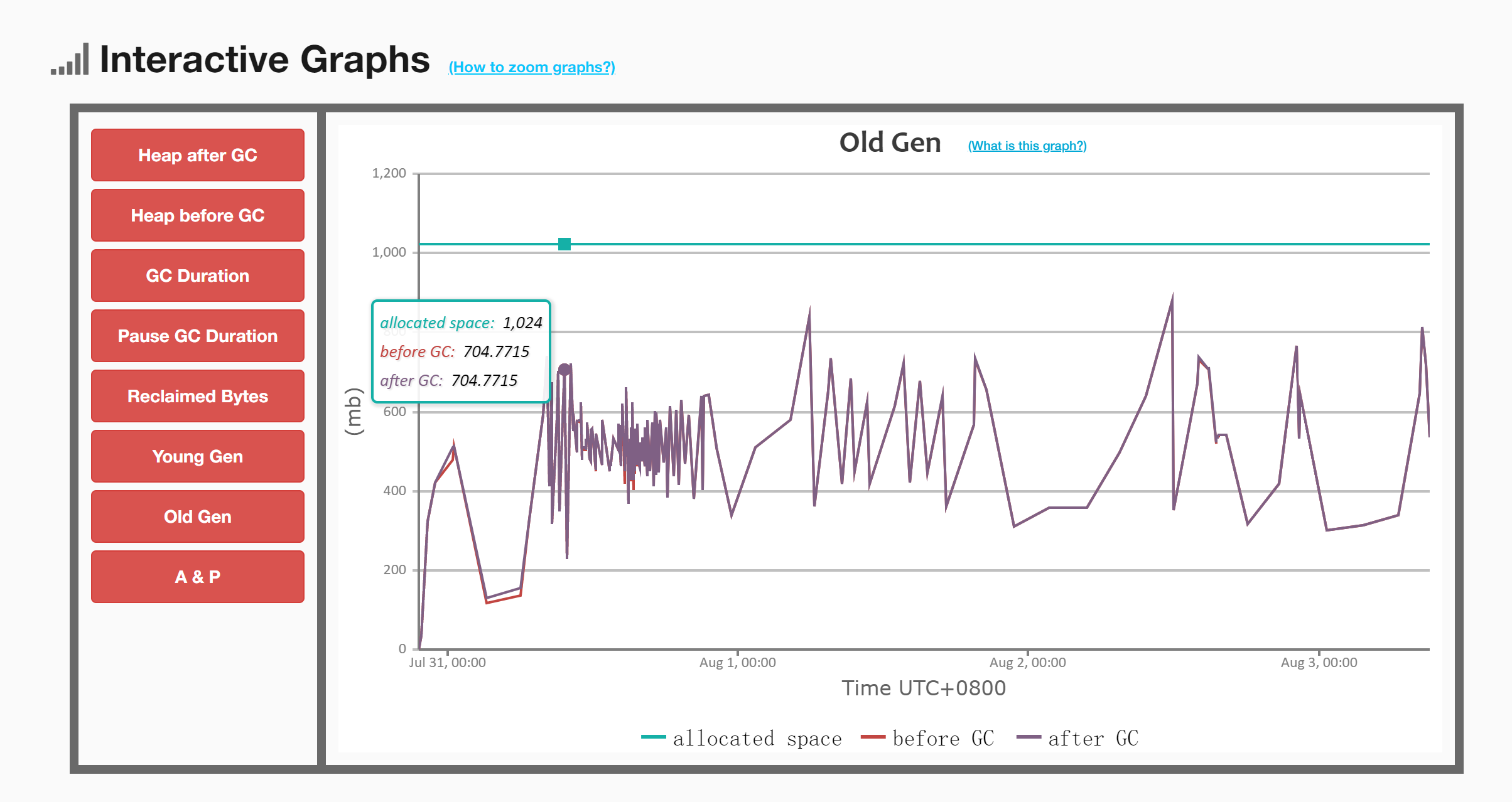
可以观察到,在Full GC之前后,老年代的内存几乎没有明显变化,红线和紫线几乎重合。这是因为 CMS 在执行Full GC时有两次 STW 的阶段,这两次都是在标记阶段。由于是标记阶段,所以老年代内存的变化不会很明显,这个所谓的老年代GC应该指的就是这两次STW。
2.3 GC前堆内存示意图
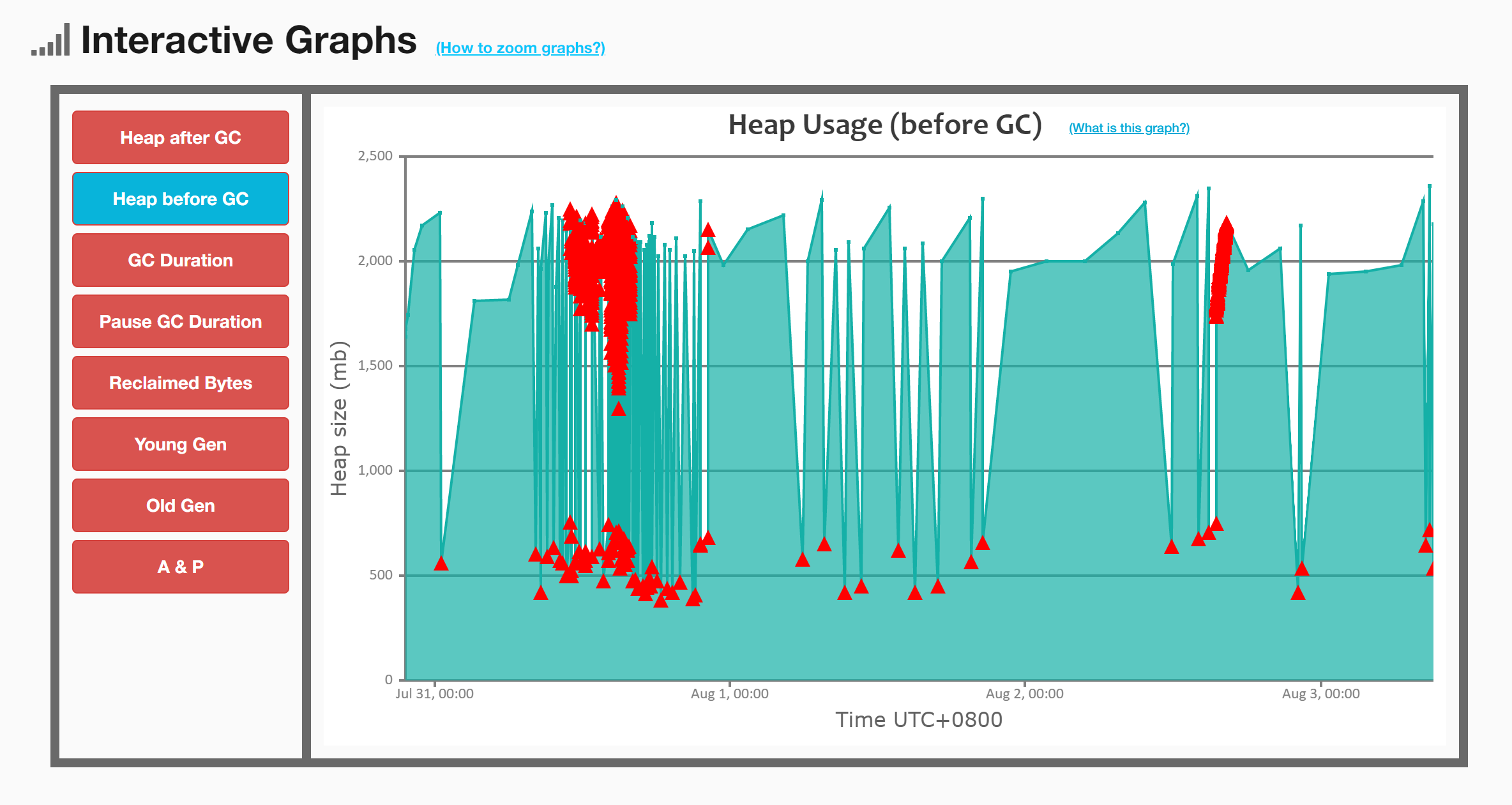
这张图GC密集的情况让人不禁一惊。
然而,基本上可以观察到,Young GC通常发生在内存使用达到一定程度后,年轻代空间不足,于是进行了Young GC。而Full GC则有一些不同,部分发生在老年代无法分配空间后,还有很多是在发生Young GC后紧接着进行的。这可能意味着这次Young GC并没有产生明显的效果。
2.4 CMS GC统计
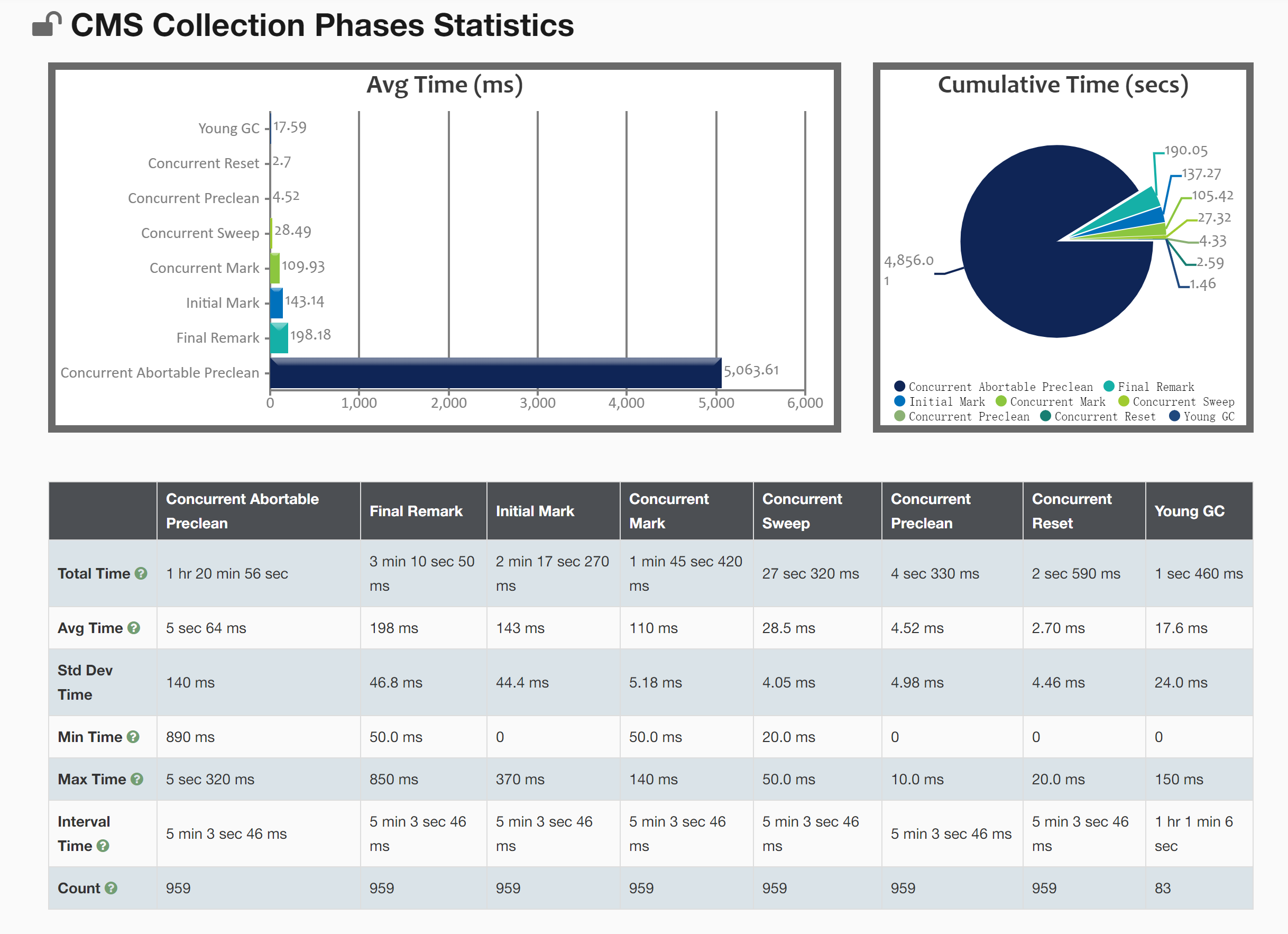
每小时进行近似11次的Full GC,平均每隔5分钟就进行一次,而这还没计算Young GC的次数。所以系统会经常性卡顿…
三、分析问题发生的原因
3.1 使用jmap查看对象
通过使用jmap -histo命令查看对象的分布状态
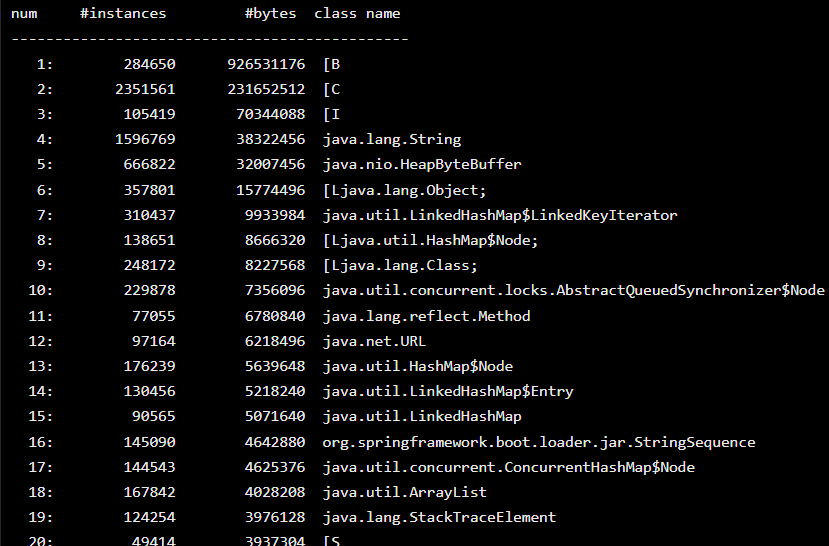
第一名是字节数组,居然有284650个实例,占用内存竟达到了883.6M字节。年轻代一共就2G…
3.2 分析大对象出现的原因
然后我开始回忆,为什么会有这么多的字节数组,以及是怎么引起了这么多次Full GC。终于想到了,这一切都源自一个前端的BUG…
H5 App端上传图片至服务端,然后服务端再转存至OSS内,由于OSS是内网服务,因此不得不采取这种方式。即便在下载图片时,也需要先将OSS内的文件下载至服务内,然后通过接口向外写流实现下载功能。
有一次发现App上传的图片居然有全黑的、没有任何图案的情况。由于服务端只校验了文件大小,没有校验图片内容,前端怀疑可能是iOS上某个系统版本内的微信BUG。由于在短时间内无法确认和解决这个问题,前端决定在服务端增加一个校验。校验的方式是使用一个算法来判断是否所有像素点的值都是相同的。只要有一点不一样,就通过校验;否则,就认为是上传失败。
问题的关键在于,这种校验实际上需要使用InputStream来进行,而流是无法复用的——读取一次后就被消耗掉,无法继续进行校验后的上传至OSS的操作。为了解决这个问题,采用了byte[]来处理。首先将流转成byte[],然后在校验时将byte[]转成ByteArrayInputStream来进行校验。校验通过后,再将byte[]转成ByteArrayInputStream进行上传至OSS内。这样的处理方式导致产生了大量的byte[]实例。
3.3 问题所在
因为这些byte[]都是方法内的局部变量,随着线程栈的程序执行,并且默认开启了逃逸分析,执行完上传方法后,这个栈帧和其中的一些局部变量就被销毁并回收了。但问题是,用户上传的图片可能非常大,甚至超过了10M。这导致InputStream对象和byte[]都变得很大,远远超过了设置的 -XX:PretenureSizeThreshold=1M 参数。
于是,这些对象不再在栈空间内创建,而是在堆空间中分配。当初设置参数时,按照常规的参数设置,并在紧急改动代码后未修改参数。忽略了一个关键点,这种大对象会直接被分配到老年代,而不是在年轻代。所以,尽管我把年轻代设置得很大,老年代设置得相对较小,实际上并没有太大的作用。我的初衷是让“朝生夕死”的对象都在年轻代被清理掉,但由于这些用于中转的byte[]对象和许多Stream对象太大,它们根本不在年轻代中(对业务的预测失误了)。
因此,稍微小一点的老年代经常被占满,导致Full GC的发生频率很高。我猜测在用户量增加、并发度上升的情况下,服务可能会陷入常规的卡顿,最终可能无法避免OOM。
四、如何解决问题
问题的原因已经猜测到了,即存在超大对象导致老年代充斥,引发频繁的Full GC。
4.1 思路1:
在代码中避免生成大对象。
4.2 思路2:
尝试让大对象分配到年轻代。
4.3. 实际采用的解决方法
由于思路1并不可行,因为前端的BUG尚未解决,服务端的校验需要一直存在。这意味着相应的代码必须一直保留,而且仍然需要使用字节数组进行中转。同时,考虑到用户上传的文件可能很大(虽然已经设置了限制,但允许超过10M),所以使用Stream也会产生大对象。因此,这种方法并不可取。
实际上,我们采用了思路2,即让大对象直接分配在年轻代内。解决方式相对简单,只需修改相应的参数即可。
# 大对象阈值设置为12M
-XX:PretenureSizeThreshold=12M
将年轻代设置为12M是在讨论后认为是一个相对合理的数值。由于目前并发不是很大,因此可以通过在年轻代解决大对象的方式,较少地影响用户体验。
五、调优效果
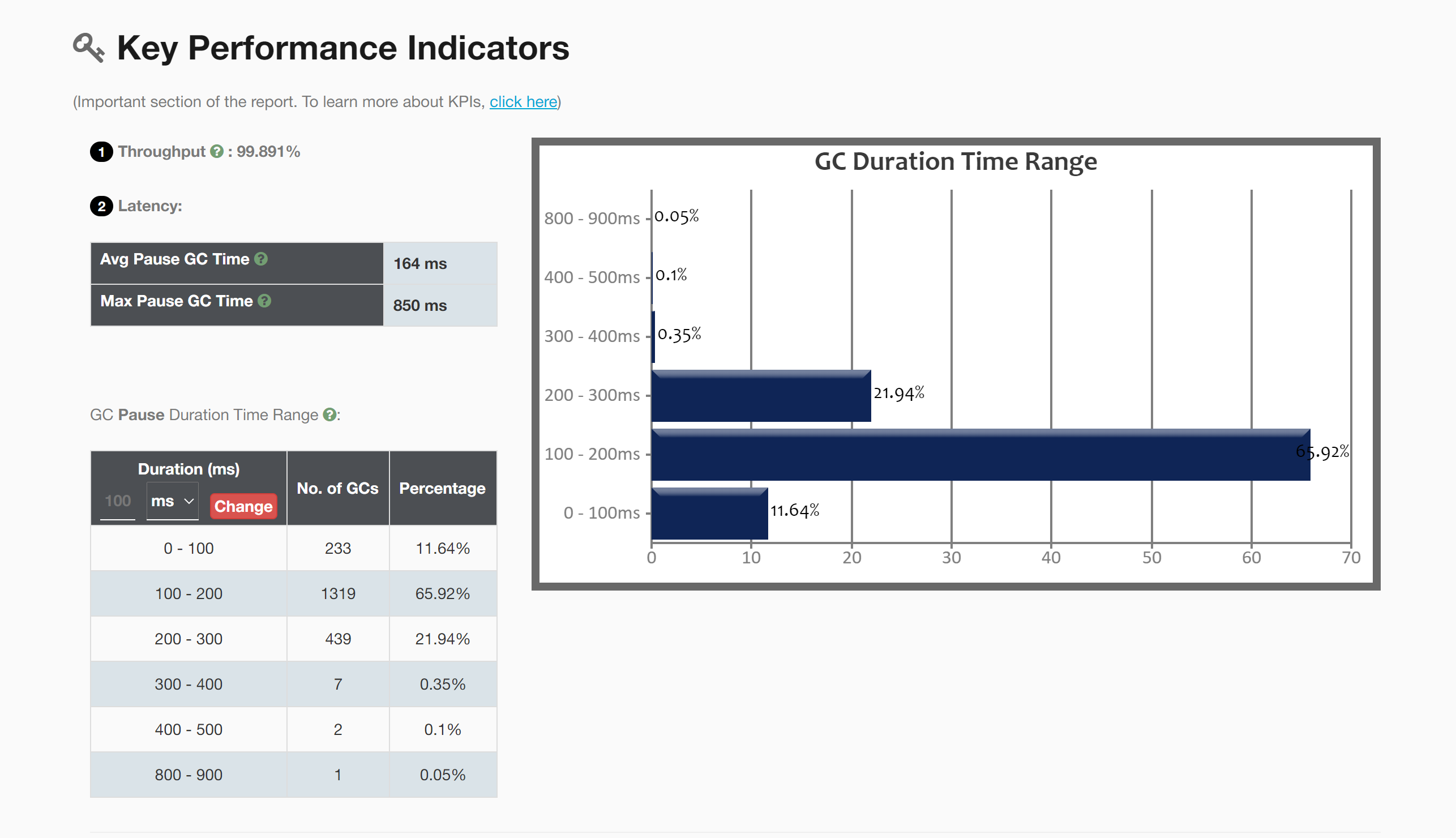
5.1 GC的时间范围
在这44小时的统计结果中,相当于前一段日志的一半时间,并且是同一台服务器。

成果喜人!竟然一次Full GC都没有发生,因此也没有CMS GC的统计图表。
从这几个表格可以看出,Full GC次数为零,Young GC只有90+次,平均每小时2次,而且每次停顿的时间仅为24毫秒,几乎可以忽略不计。
5.2 看一下年轻代空间的GC前后的变化
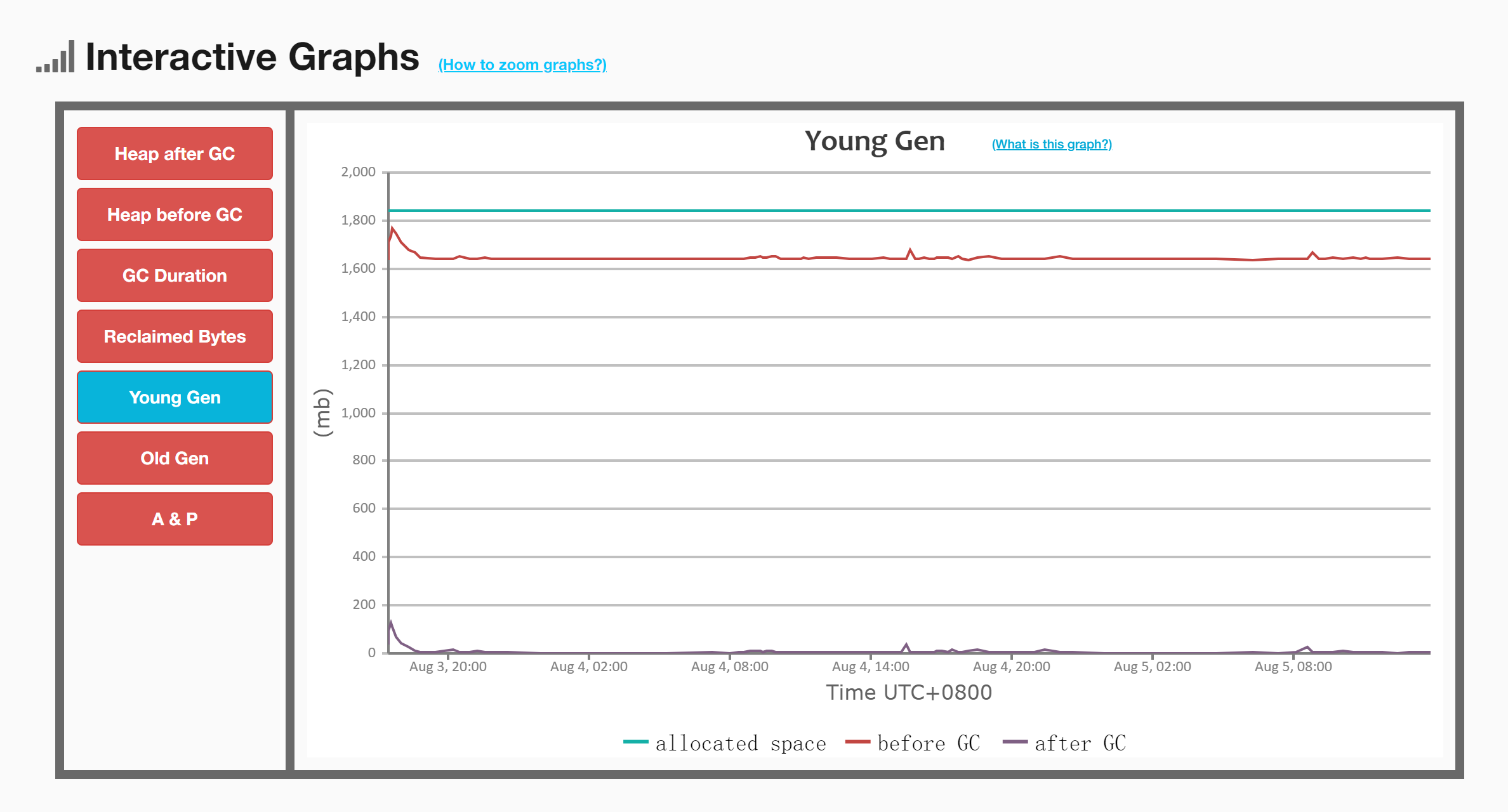
可以看出,几乎每次GC后,年轻代的空间都几乎被完全清空了,说明GC的效果非常显著且有效。
5.3 看一下老年代空间的GC前后的变化
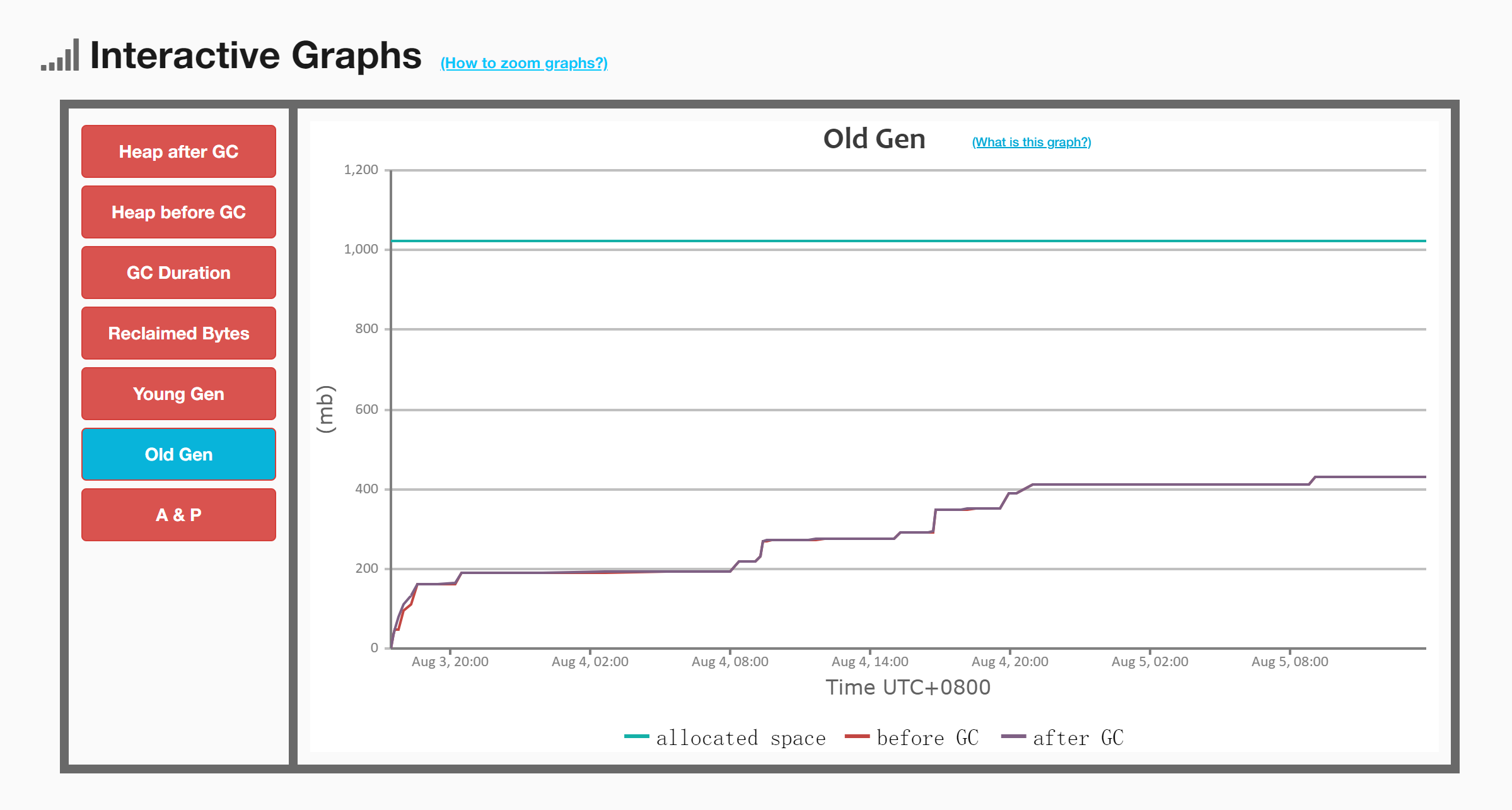
因为没有Full GC,所以发生的都是Young GC。可以发现,在服务器启动的几个小时后,老年代空间比做GC前稍微大了一点。之后的内存增长速率完全和GC没关系了,这也符合我们参数的预测。
由于(-XX:MaxTenuringThreshold=5 )最大分代年龄为5,能够熬过5次Young GC的对象,例如Spring IOC容器内的bean和一些缓存对象,这些属于“老不死”对象。设置为5可以让这些对象尽早进入老年代,不占用年轻代空间。因此,前几个小时经历5次GC后,老年代空间出现了增长的波动,应该是这些“老不死”对象。
之后老年代空间的增长与GC没关系,GC前后空间是不变的。当然,老年代本身也在缓慢增长,直到最后的几个小时,增速已经平缓。之后老年代缓存增长,最终也许会导致Full GC,但没关系,已经43小时都没有Full GC,说明整体是非常稳定的!
评论区